
On Wednesday, November 25th 2020, Amazon Web Service’s US-EAST-1 Region experienced a multi-hour outage which affected a large portion of the internet.
The trigger for the disruption was the small addition of capacity to AWS’s Kinesis service, which is used to support a significant number of other AWS offerings. The Kinesis servers create new threads for other servers involved with the AWS front-end in order to communicate with one another. The extra capacity caused the servers to exceed the maximum number of allowed threads. For more information, you can read the RCA document by AWS.ֿ
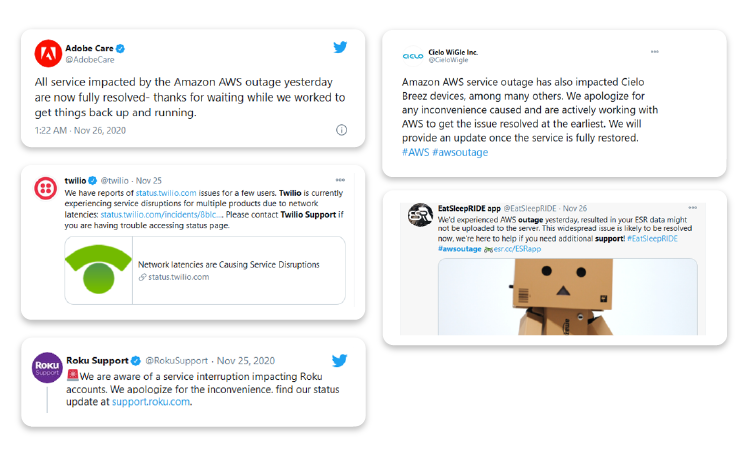
More than 100+ companies were impacted by the outage, including Adobe, Flickr, Twilio, Roku, TribunePublishing, The Wall Street Journal, The Washington Post, and Amazon’s smart security division.
Among the organizations impacted by the breach were:
o Target-owned Shipt delivery service, which was able to receive and process some orders, although it stated that it was taking steps to manage capacity due to the outage.
o Photo storage service Flickr, which tweeted that customers were unable to log in or create accounts.
o Streaming service Roku, which experienced problems with new account activation.
Don’t assume an outage will never affect your region. A region outage can completely knock out your services and critically affect your business application’s availability for a certain period--especially if your application is built around a single-region architecture, instead of following a multi-region DR strategy.
.png)
In other words, DON’T PUT ALL YOUR EGGS IN ONE BASKET. You can split the traffic between regions using a globalDNS load-balancer, and in the event of a region-level disaster, you’ll still have another region that’s running.
Using a Single Cloud Service provider can be counter-productive in such scenarios. Develop a strategy for adopting Hybrid-Cloud or Multi-Cloud.
If you want to avoid having your entire system knocked out in the event of region-level outage, you’ll need to involve cross-region backups in your DR plan. Your critical data needs to be backed up in multiple regions, following security best practices around data.
Being proactive when outages occur is essential to help limit the impact. Immediate impact analysis is critical. You should be ready to assess the impact as soon as it occurs and map it to business functionalities to be able report it to your business team accurately.
Lightlytics calculates the impact radius when services fail and maps it to business functionality, presenting all the infrastructure components and business services that are impacted due to outages.
Making sure your multi-region strategy will work when needed.
When managing production workloads across regions, you’ll need to ensure your configurations and services are synced and ready to work the moment they are needed. You’ll need to validate that there are no cross-region dependencies that could potentially impact operations once failure occurs and that your load-balancing rules will work correctly once the failure happens.
With Lightlytics, you can validate all of the above automatically and get the confidence you need to make sure things continue to work, even when the worst happens.











